※ 이 글을 쓰는 사람은 SW 비전공자입니다.
※ 개인 공부를 위해 정리하는 글이며, 작성한 코드들은 효율성, 깔끔함(?) 등과는 거리가 멀 수 있습니다.
1편 : 2021.03.31 - [코딩/Python] - [Python/파이썬] Pandas 기초 정리 : Series, Dataframe 개념 정리
2편 : 2021.04.01 - [코딩/Python] - [Python/파이썬] Pandas 기초 정리 : 엑셀 파일(.xlsx) Dataframe으로 만들기
3편 : 2021.04.03 - [코딩/Python] - [Python/파이썬] Pandas 기초 정리 : Dataframe 내부 데이터 조회 방법
4편 : 2021.04.05 - [코딩/Python] - [Python/파이썬] Pandas 기초 정리 : Dataframe 행, 열 추가 방법
5편 : 2021.04.11 - [코딩/Python] - [Python/파이썬] Pandas 기초 정리 : Dataframe 행, 열 삭제하기(drop 함수)
6편 : 2021.04.13 - [코딩/Python] - [Python/파이썬] Pandas 기초 정리 : 원소바꾸기, dropna(), fillna()
7편 : 2021.04.24 - [코딩/Python] - [Python/파이썬] Pandas Dataframe 결합 : Concat
8편 : 2021.04.25 - [코딩/Python] - [Python/파이썬] Pandas Dataframe 결합 : Merge
이전 포스팅에서 Series와 Dataframe에 대한 개념에 대해 정리하고, pandas 모듈을 통해 어떻게 생성할 수 있는지에 대해 공부했다. pandas 모듈을 활용하면 이미 만들어져있는 엑셀파일이나 csv 파일을 Dataframe으로 만들어 여러 방법으로 가공할 수 있다. 이 가공한 Dataframe을 다시 csv나 엑셀파일로도 만들 수 있다.
나는 엑셀 파일을 활용할 예정이기 때문에 이번 포스팅은 엑셀파일을 Dataframe화 하는 방법에 대해 정리해보려고 한다. 임의의 엑셀파일 df_test.xlsx를 생성하고 아래와 같이 시트를 작성해보았다.(시트명 : Sheet1)
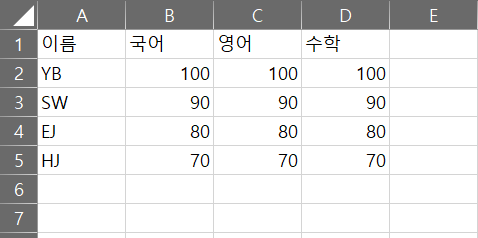
1. 엑셀 파일(.xlsx)를 Dataframe으로 생성하는 법
※ 기본 사용법
import pandas as pd
pd.read_excel("파일명(경로포함)", engine = "openpyxl)-. pandas의 read_excel 함수를 사용하면 된다. 작성 중인 .py파일과 같은 경로에 있으면 파일명만 넣으면 된다.
-. xlsx 확장자의 엑셀파일을 dataframe 하려면 openpyxl 엔진을 활용해야 한다.
-. 위 사용법에 따라 df_test.xlsx 파일 내부 내용을 dataframe화 해보자.
<코드>
import pandas as pd
#df_test.xlsx 파일을 dataframe으로 변경
df = pd.read_excel("df_test.xlsx", engine = "openpyxl")
print(df)
이름 국어 영어 수학
0 YB 100 100 100
1 SW 90 90 90
2 EJ 80 80 80
3 HJ 70 70 70
2. read_excel 함수의 각 옵션
read_excel 함수에는 여러 파라미터가 있다. 파라미터를 활용하면 dataframe을 내가 원하는 방향으로 좀 더 쉽게할 수 있는 것 같다. 대표적으로 잘 쓸 것같은 파라미터를 정리해보려고 한다. 엑셀파일은 위 예시 파일 그대로 활용한다.
아래는 대표적인 파라미터만 몇개 기재한거라 더 많은 내용을 참고하려면 다른 블로그에서 잘 정리해주신 분이 있어서 하단의 참고링크를 기재하였음.
1) sheet_name
-. 엑셀 파일에 여러 시트가 있을 경우에 자기가 원하는 시트를 Dataframe화 하라면 사용하는 파라미터이다.
<코드>
import pandas as pd
#여러 시트가 있을 경우 시트명을 직접 입력하여 dataframe화
df = pd.read_excel("df_test.xlsx", engine = "openpyxl", sheet_name="Sheet1")
print(df)
이름 국어 영어 수학
0 YB 100 100 100
1 SW 90 90 90
2 EJ 80 80 80
3 HJ 70 70 70
2) header
-. header는 행의 제목이 실행되는 위치를 지정할 수 있다.
-. 예를 들어 제목행이 아래처럼 3행에 있는 경우 header=2를 입력하면 된다.
-. 2를 입력하는 이유는 파이썬의 인덱싱 시작 숫자는 0이기 때문이다. (0,1,2이므로 3행은 2로 입력)
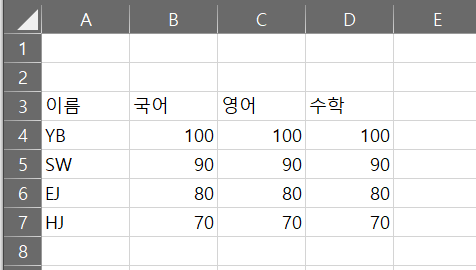
<코드>
import pandas as pd
#header를 통해 컬럼명 위치 지정 가능
df = pd.read_excel("df_test.xlsx", engine = "openpyxl", header=2)
print(df)
이름 국어 영어 수학
0 YB 100 100 100
1 SW 90 90 90
2 EJ 80 80 80
3 HJ 70 70 70
3) index_col
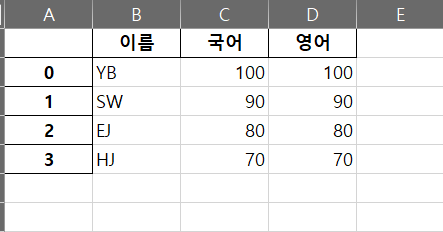
-. 특정 열(Column)을 인덱스로 지정하고 싶을 때 사용한다.
-. 만약 위 Dataframe에서 '이름' 열을 인덱스로 하려면 2가지 방법이 있다.
index_col = "이름" 또는 index_col = 0
-. 0을 입력하는 이유는 파이썬 인덱싱이 첫번째가 0부터 시작하기 때문이다.(이름열이 Dataframe에서 첫번째임)
<코드>
import pandas as pd
#index_col = 0으로 입력해도 결과는 동일
df = pd.read_excel("df_test.xlsx", engine = "openpyxl", index_col="이름")
print(df)
국어 영어 수학
이름
YB 100 100 100
SW 90 90 90
EJ 80 80 80
HJ 70 70 70
4) usecols
-. usecols는 엑셀 파일에서 특정 열(Column)들만 골라서 Dataframe화 할 때 사용한다.
-. 위 엑셀파일에서 이름이랑 영어점수만 Dataframe으로 생성하고 싶다면 usecols = "A, C" 를 입력한다.
-. 알파벳말고 숫자 인덱싱으로도 접근 가능하다. A,C열이면 usecols = [0, 2]를 입력해도 같은 결과이다.
<코드>
import pandas as pd
#원하는 열만 데이터프레임화
df = pd.read_excel("df_test.xlsx", engine = "openpyxl", usecols = "A,C")
print(df)
이름 영어
0 YB 100
1 SW 90
2 EJ 80
3 HJ 70
5) names
-. Column 명의 제목을 바꾸고 싶을 때 사용하는 파라미터
-. 이름, 국어, 영어, 수학을 'Name', 'Korean', 'English', 'Math'로 바꿔보자.
-. 주의할 사항은 해당 dataframe의 Column 숫자만큼 names를 설정해야 한다.
(아래처럼 원래 Column이 4개였으면 names의 리스트 요소도 4개
<코드>
import pandas as pd
#원하는 열만 데이터프레임화
df = pd.read_excel("df_test.xlsx", engine = "openpyxl", names=['Name', "Korean", "English","Math"])
print(df)
Name Korean English Math
0 YB 100 100 100
1 SW 90 90 90
2 EJ 80 80 80
3 HJ 70 70 70
3. Dataframe을 다시 엑셀파일(.xlsx)로 저장하기
-. Dataframe을 다시 엑셀파일(.xlsx)로 저장할 수 있다.
-. Dataframe의 인덱스 때문에 원래 형태와는 다른 포맷이 출력된다.(아래 참고)
<코드>
import pandas as pd
#원하는 열만 데이터프레임화(A,B,C)
df = pd.read_excel("df_test.xlsx", engine = "openpyxl", usecols=[0,1,2])
print(df)
#데이터프레임 엑셀파일로 추출
df.to_excel('test_save.xlsx')
이름 국어 영어
0 YB 100 100
1 SW 90 90
2 EJ 80 80
3 HJ 70 70
다음 포스팅에서는 만들어진 Dataframe을 가공하는 방법이나 문자열을 찾는 방법 등의 padnas 함수를 정리해 볼
예정이다.
참고링크 : ddolcat.tistory.com/671 - read_excel 함수의 파라미터 정리 참고
[Python] 파이썬 판다스(pandas)를 사용하여 엑셀(xlsx, csv)파일로 저장하는 방법 : numpy, openpyxl, to_excel(
판다스(pandas)는 데이터 분석을 위해 많이 사용되는 모듈입니다. xlsx, csv파일을 읽어와서 DataFrame으로 가져올 수 있습니다. 또다른 방법은 웹 크롤링을 하여 가져올 수 있습니다. 판다스(pandas)를
ddolcat.tistory.com
'코딩 > Python' 카테고리의 다른 글
| [Python/파이썬] Pandas Dataframe 결합 : Merge (0) | 2021.04.25 |
|---|---|
| [Python/파이썬] Pandas Dataframe 결합 : Concat (0) | 2021.04.24 |
| [Python/파이썬] PyQt5 사용시 필요한 쓰레드 개념 이해 : 파이썬 GUI 응답없음 해결 방법 - 2 (11) | 2021.03.30 |
| [Python/파이썬] PyQt5 사용시 필요한 쓰레드 개념 이해 : 파이썬 GUI 응답없음 해결 방법 - 1 (2) | 2021.03.29 |
| [Python/파이썬] PyQt5를 통한 GUI 구성 및 사용법 이해하기 (2) | 2021.03.28 |

