이번 포스팅은 Softmax Regression(소프트맥스 회귀) 알고리즘에 대한 내용을 간단하게 정리한다. 참고로 소프트맥스 회귀는 이전 로지스틱 회귀의 확장판이라고 할 수 있다. 로지스틱 회귀는 둘 중에 하나를 선택하는 이진 분류에 대한 내용이었다면 소프트맥스 회귀는 여러개의 선택지 중에 하나를 선택하는 다중분류 알고리즘이기 때문이다.
1. Softmax Regression(소프트맥스 회귀)
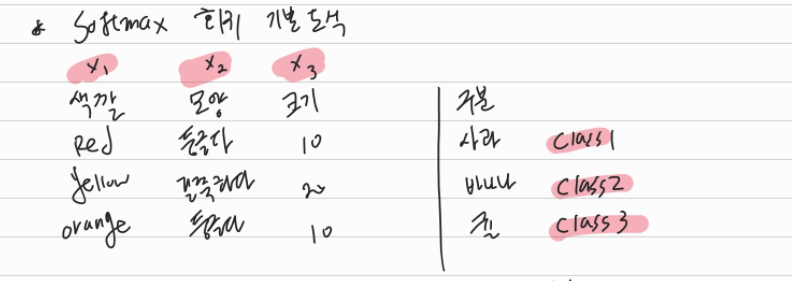
소프트맥스 회귀는 각 데이터 샘플에 대한 특성(X1, X2, X3)에 따라 가장 확률적으로 가까운 출력값(레이블)을 찾는 것이다. 이를테면, 위 데이터 샘플 중 1개인 X1(색깔)이 "Red", X2(모양)이 "둥글다", X3(크기) 10이면 Class(사과1)라는 정답을 찾는 것이다. 위 이미지는 쉽게 예를 들기 위해 X1, X2는 Red, 둥글다 등 문자를 입력값으로 했지만 실제 알고리즘상 입력값은 어떤 수치가 될 수 있다.
소프트맥스 회귀의 알고리즘 진행과정을 아래와 같이 도식화해보았다. 소프트 맥스 회귀의 진행 순서는 아래와 같다.

1) 입력(X1,X2,X3)
위 그림의 예시에는 특성이 3개(X1, X2, X3), 레이블이 3개(Class1, Class2, Class3)지만 실제로는 특성과 레이블 숫자가 다를 수도있다. 특성이 4개(X1, X2, X3, X4)이고 레이블이 3개(Class1, Class2, Class3)일 수도 있는 것이다. 이 입력값은 Softmax(WX+B)라는 함수를 거쳐 출력 레이블 개수에 맞는 각각의 확률값을 갖게 된다.
2) 예측값
예측값을 말그대로 각 구분(Class1, Class2, Class3)가 정답일 확률이 얼마이냐 하는 것이다. 확률이기 때문에 각 클래스 예측값의 합은 1이 되어야 한다. 위 예시로 들자면 0.5인 Class3가 가장 높기 때문에 '귤'일 확률이 높다고 표현할 수 있다. 소프트맥스 회귀 알고리즘은 실제값과 비교해서 실제값이 '귤'이라면 학습을 통해 '귤'일 확률이 높게 나오도록 가중치 W와 편향 B를 학습시킬 것이다. 그 것은 3)의 오차 비교 및 학습에서 진행하게 된다.
'
3) 오차 비교 및 학습
실제값과 예측값을 비교하여 정답을 맞출 수 있는 확률이 높아지도록 W와 B를 학습시키는 과정이다. 그 전에, 그림을 보면 Class1, Class2, Clas3를 각각 (1,0,0), (0,1,0), (0,0,1)로 표현하는 그림이 나온다. 각 Class가 정답인 실제값을 원-핫 벡터(One-Hot Vector)라는 방식으로 표현한 것이다. 원-핫 벡터 방식을 간단하게 설명하자면, 다중 Class 분류 문제에서 각 Class간의 관계를 균등하게 표현할 수 있도록 한 방식이라고 이해하면 될 것 같다. 소프트맥스 회귀에서는 원-핫 벡터 방식을 사용해서 실제 각 레이블이 정답일 확률을 100%(숫자 1)로 표현하여 예측값과 비교하고, W,B를 업데이트한다.
2. Softmax Regression(소프트맥스 회귀)의 Cost Function
1) Softmax(WX+B)에서 W와 B의 행렬 크기 알기
소프트맥스 회귀의 Cost Function(손실 비용 함수)를 알기 전에 소프트 맥스 함수의 입력값 softamx(WX+B)에서 W와 B가 행렬로 어떻게 표현되는가를 정리해보았다. 실제 파이썬으로 구현할 때, W와 B의 행렬 크기를 아는 것을 중요하기 때문이다.

각 샘플의 특성 개수가 3개(X1,X2,X3)이고 각 Class의 개수가 3개(Y1,Y2,Y3)인 경우 표현을 위와 같이 할 수 있다. 데이터 샘플 개수가 n이라면(X의 행개수) 가중치 W는 3*3 행렬, B를 n*3 행렬이 될 것이다.
2) Cost Function(손실 비용 함수)
먼저 샘플 데이터가 1개일 때, Cost Function은 아래와 같다. 노란색으로 표시 된 k는 출력 레이블(Class)의 개수이다. 위 예시로 따지면 Class가 3개이므로 k=3이다. Yj는 실제값이므로 각 출력 레이블의 원-핫 벡터값이 될 것이다. 예를 들면, Class 1인경우 원-핫벡터가 (1,0,0)이므로 K=1인경우만 Yj=1이된다. 즉,각 출력 레이블 요소의 log(확률)값이라고 요약할 수 있다.
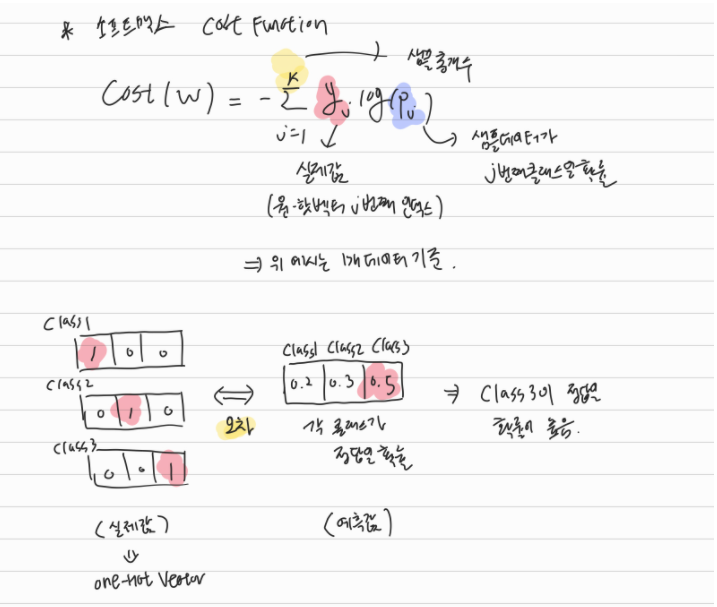
선형회귀, 로지스틱회귀와 동일하게 딥러닝 알고리즘은 Cost = 0에 가까워지는 W와 B를 찾게 된다. 즉, 위 수식에서
Pj=1일 때 log1=0이 되므로 각 레이블의 확률값이 1이 되는 방향으로 W와 B를 학습해간다.(실제 원핫벡터의 각 레이블 요소의 값이 1인 것을 기억해보자.)

이번 편에서는 간단히 소프트맥스 회귀에 대한 이론만 정리해보았고 다음 포스팅에서 실제 구현 코드에 대한 정리를 해볼 예정이다.
'코딩 > Deep Learning' 카테고리의 다른 글
| [파이썬/Pytorch] 딥러닝 - CNN(Convolutional Neural Network) 2편 : Padding, Pooling (0) | 2021.09.22 |
|---|---|
| [파이썬/Pytorch] 딥러닝- CNN(Convolutional Neural Network) 1편 (0) | 2021.09.14 |
| [파이썬/Pytorch] 딥러닝 - Softmax Regression(소프트맥스 회귀) 2편 (0) | 2021.08.08 |
| [파이썬/Pytorch] 딥러닝 - Logistic Regression 이해를 위한 정리 (0) | 2021.08.01 |



